=Overview
We propose the Neuro-Symbolic Concept Learner (NS-CL), a model that learns visual concepts, words, and semantic parsing of sentences without explicit supervision on any of them; instead, our model learns by simply looking at images and reading paired questions and answers.

Figure 1: An example image-question pair from the VQS dataset and the corresponding execution trace of the proposed NS-CL.
Our model builds an object-based scene representation and translates sentences into executable, symbolic programs. To bridge the learning of two modules, we use a neuro-symbolic reasoning module that executes these programs on the latent scene representation. Analogical to human concept learning, the perception module learns visual concepts based on the language description of the object being referred to. Meanwhile, the learned visual concepts facilitate learning new words and parsing new sentences. We use curriculum learning to guide the searching over the large compositional space of images and language. Extensive experiments demonstrate the accuracy and efficiency of our model on learning visual concepts, word representations, and semantic parsing of sentences. Further, our method allows easy generalization to new object attributes, compositions, language concepts, scenes and questions, and even new program domains. It also empowers applications including visual question answering and bidirectional image-text retrieval.
=Framework
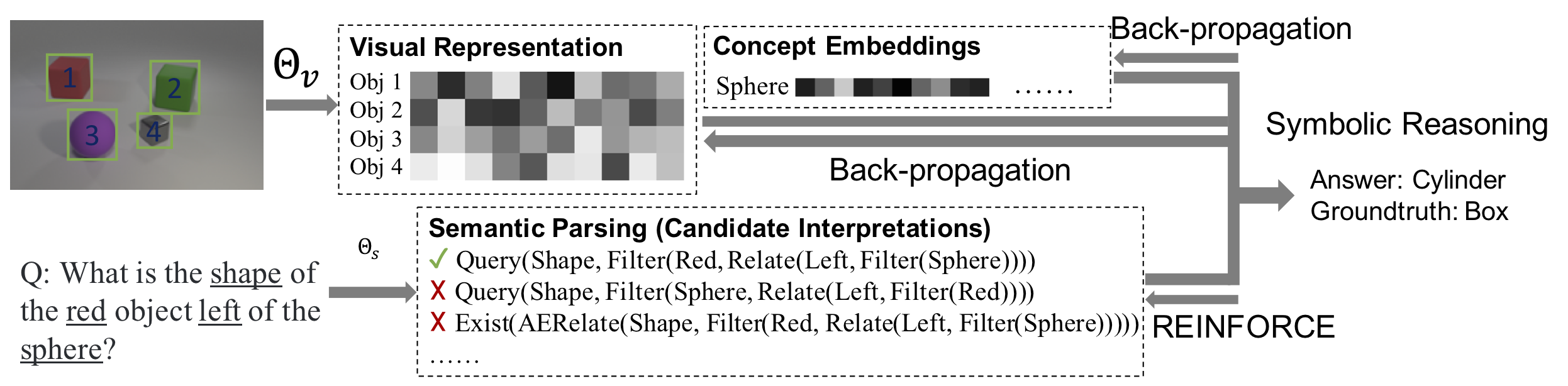
Figure 2: We first use a visual perception module to construct an object-based representation for a scene, and run a semantic parsing module to translate a question into an executable program. We then apply a quasi-symbolic program executor to infer the answer based on the scene representation. We use paired images, questions, and answers to jointly train the visual and language modules..
- The perception module.
- Given the input image, we generate object proposals, and extract visual representations for each of the proposal.
- The semantic parsing module.
- The semantic parsing module translates a natural language question into an executable program with a hierarchy of primitive operations. Each concept in the program corresponds to a vector embedding that is jointly trained.
- The quasi-symbolic reasoning module.
- Given the recovered program, a symbolic program executor executes the program and derives the answer based on the object-based visual representation and the concept embeddings. Our program executor is a collection of deterministic functional modules.
=Resources
- The Neuro-Symbolic Concept Learner in [PyTorch (Official)].
- [Poster] presented at ICLR 2019.
- [Talk slides] presented at ICLR 2019.
=Related Publications
Visual Concept-Metaconcept Learning
(*: First two authors contributed equally.)Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
- NeurIPS 2018 (Spotlight)
- Paper /
- Project Page /
- BibTeX